자연어 처리의 진화: 분산된 인공지능에서 기초 모델로
정의
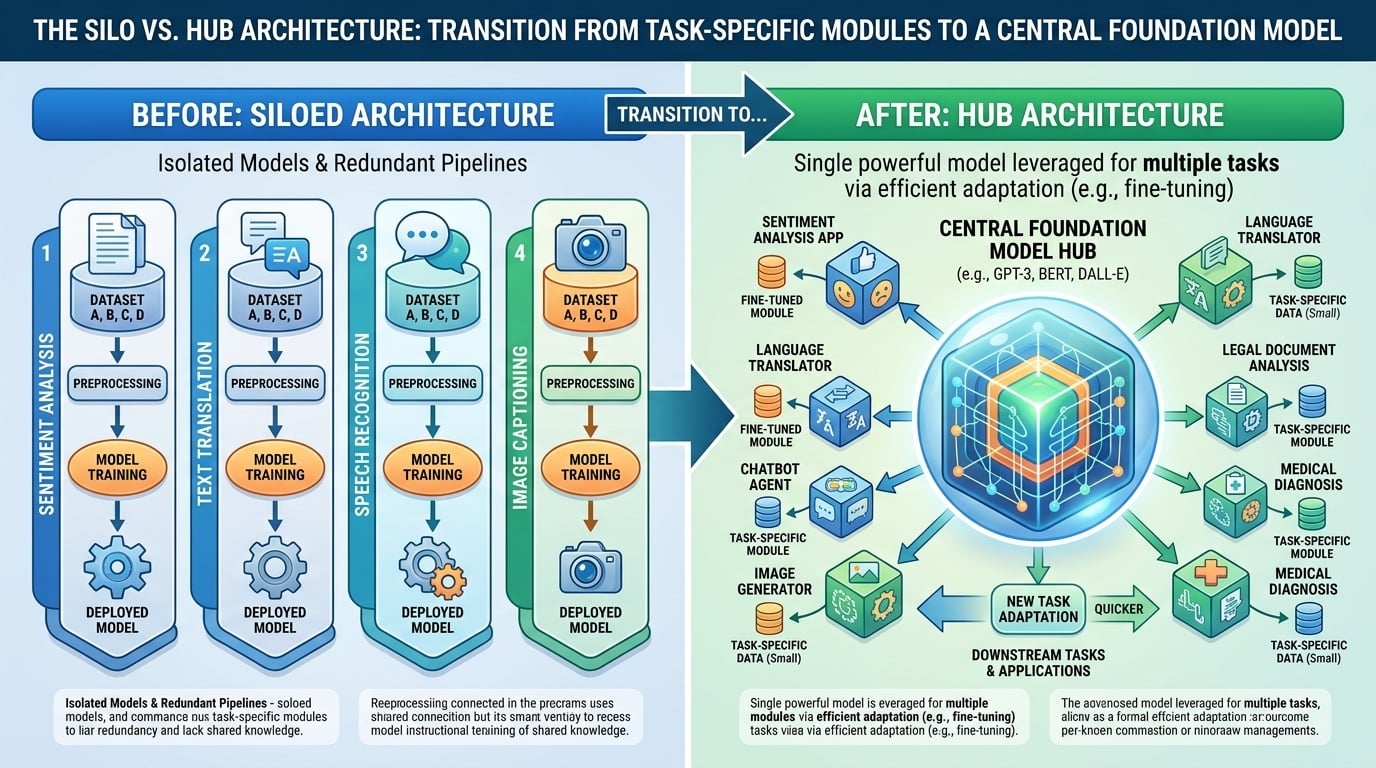
- 분산된 인공지능: 시퀀스 레이블링이나 분류와 같은 개별 작업을 위한 특수 설계된 신경망 아키텍처로 구분되는 시대.
- 기초 모델: 모든 언어 문제를 생성형 텍스트-텍스트 시퀀스 $x \rightarrow y$로 간주하는 통합적이고 단일 구성의 트랜스포머 아키텍처.
핵심 개념
- 아키텍처 통합: 과거에는 자연어 처리가 맞춤형 파이프라인(개체명 인식에 사용하는 양방향 LSTM, 감성 분석에 사용하는 컨볼루션 신경망)을 필요로 했다. 대규모 언어 모델은 이러한 사각지대를 하나의 중심 구조로 압축하여, 동일한 가중치가 모든 작업에 활용된다.
- 통합 인터페이스: LLM은 특수한 "출력 헤드" (예: 3개 클래스 소프트맥스)를 자연어 인터페이스로 대체한다. 입력과 출력은 항상 문자열이며, 모델이 intent 보다는 형식.
- 지식 전달: 전통적인 모델은 각 작업에 대해 "백지 상태"였다. 대규모 언어 모델은 일반화 우선특정 작업이 이미 존재하는 강력한 언어 내부 표현의 단순 응용이라는 점을 우선시한다.
역사적 맥락
- 2018년 이전: 작업 격리가 서로 다른 손실 함수 $\mathcal{L}_{task}$를 가진 별도의 모델을 훈련해야 하는 요구를 초래했다.
- 현대 시대: "텍스트-텍스트" 패러다임은 하나의 모델(예: Llama-3)이 제로샷 또는 피셜샷 프롬프팅을 통해 작업을 전환할 수 있게 한다.
파이썬 구현 비교